Yaduha · LLM-RBMT for Owens Valley Paiute
Fine-tuning a 3B open model to produce schema-constrained structured output that outperforms gpt-4o-mini on the cheat-proof comparator metric — a proof-of-concept for endangered-language translation via small, deployable local models.
Overview
Yaduha is a type-safe framework for structured language translation: the LLM emits a Pydantic-modelled grammar tree (subject, verb, object, nominalizer, tense, proximity, etc.), and a deterministic renderer converts it to surface form. The lead target language is Owens Valley Paiute (OVP), a no-resource language with ~40 documented nouns and ~37 verbs in the current dictionary.
The experimental pipeline evaluates a forward model (English → structured JSON) against a fixed strong model (gpt-4o-mini) serving as the decoder. Scoring is done on two arms:
- backwards — strong LLM sees the full structured JSON (including OOV English lemmas) and produces natural English.
- comparator — same, but OOV lemmas are masked to
[NOUN]/[VERB]. Cheat-proof: the decoder can't just pass English through.
Methodology
Synthetic data generation
~$0.30 at gpt-4o-mini produces a ~4,400-pair SFT dataset
covering the behaviours we want the small model to learn:
- Structure sampling — stratified across SV / SVO, nominalization, multi-clause (1–3 clauses per record), and deliberate OOV injection.
- Paraphrase menu — 8 transforms
(
add_adverbial,passivize,substitute_rare_vocab, etc.) applied to each canonical rendering to teach surface-form robustness. - OOV substitution — positive pairs (chihuahua→dog) teach hypernym collapse; negative pairs (laptop) teach when to emit a placeholder.
- Proper nouns with coreference — single-mention ("Susan runs") and multi-clause coref ("Susan eats and she drinks") teach name-as-placeholder plus pronoun resolution on second reference.
- Decoder pairs — clean and OOV-masked
backward-direction pairs so a separate backward adapter can learn to
preserve
[NOUN]/[VERB]verbatim.
Training
LoRA fine-tune of Qwen/Qwen2.5-3B-Instruct (r=16, α=32,
all linear projections, bf16) via HF TRL + PEFT — no Unsloth or
bitsandbytes (which pin against older torch), so the pipeline runs cleanly on
torch 2.11 + CUDA 13. 1 epoch, effective batch 8, cosine schedule,
completion-only loss. Runs in ~45–60 min on a single RTX 5000 Ada.
Structured output is preserved, not replaced
Training shifts the model's preferred-token distribution toward
schema-valid outputs without changing the inference stack: the
EnglishToSentencesTool still passes response_format
to the Pydantic SentenceList schema. The fine-tune makes the schema constraint
a guardrail (near-no-op) rather than a forcing function — 97% of the
time the raw generation already parses.
Results
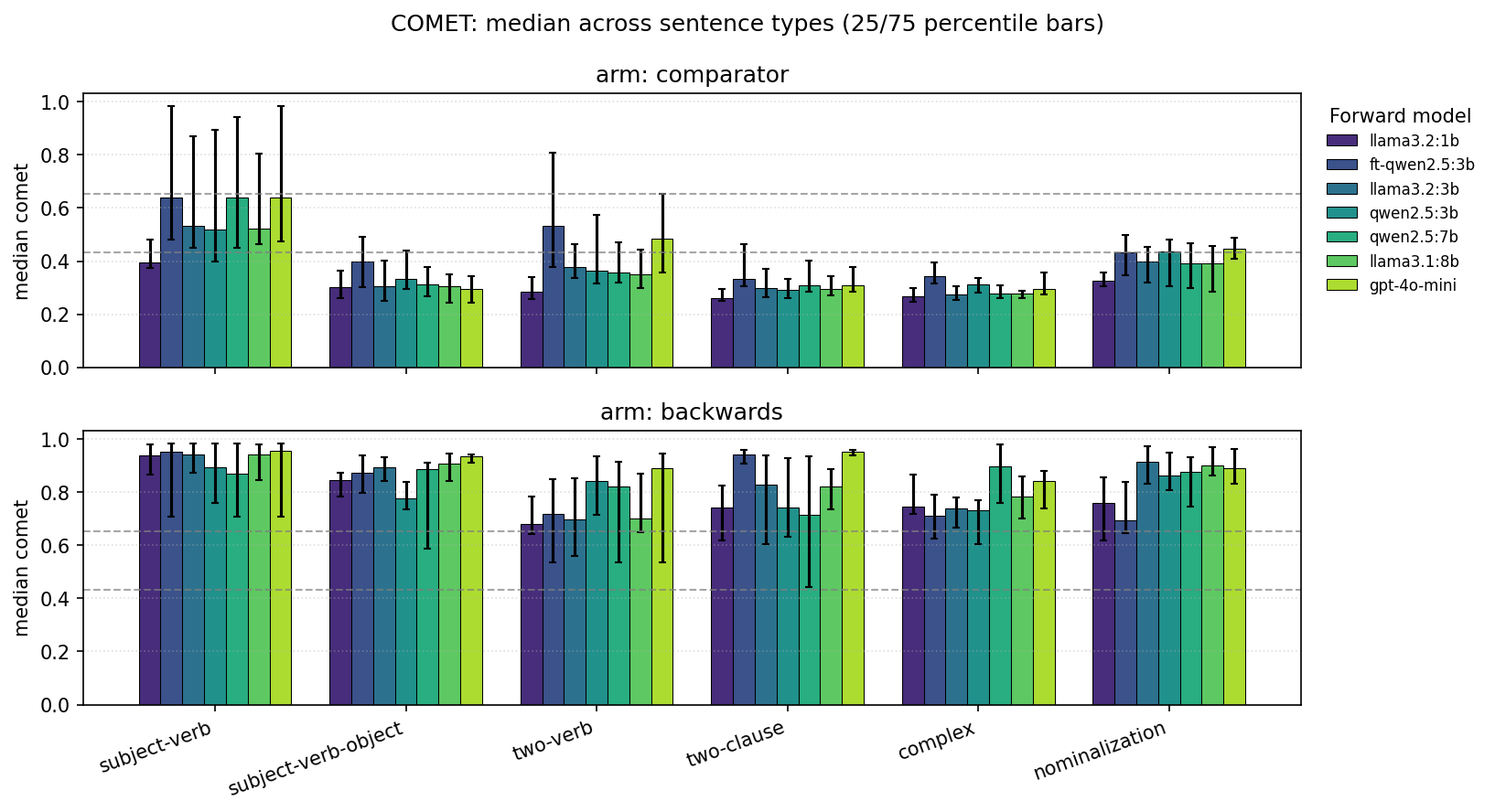
Evaluated on the full 150-sentence eval set (6 sentence types × 25 each). COMET scores are over the cheat-proof comparator arm (higher = better structural choices that preserve meaning without leaning on English passthrough).
Aggregate comparator scores (all sentence types)
| Model | Parse errs | COMET_b | COMET_c | Params |
|---|---|---|---|---|
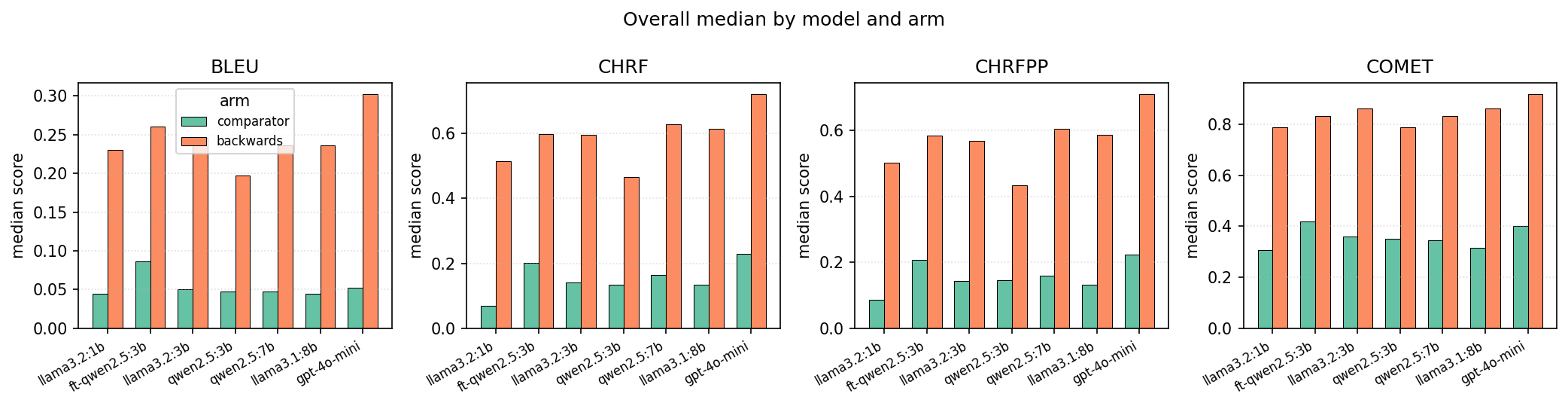
| llama3.2:1b | 9 | 0.787 | 0.306 | 1B |
| qwen2.5:3b (base) | 15 | 0.771 | 0.430 | 3B |
| llama3.2:3b | 5 | 0.861 | 0.413 | 3B |
| qwen2.5:7b | 3 | 0.834 | 0.430 | 7B |
| llama3.1:8b | 9 | 0.821 | 0.389 | 8B |
| gpt-4o-mini | 0 | 0.865 | 0.461 | ~? (API) |
| ft-qwen2.5:3b (this work) | 0 | 0.792 | 0.492 | 3B + LoRA |
Per-type comparator COMET vs gpt-4o-mini
| Sentence type | gpt-4o-mini | ft-qwen2.5:3b | Δ |
|---|---|---|---|
| subject-verb | 0.709 | 0.710 | ˜tie |
| subject-verb-object | 0.344 | 0.441 | +28% |
| two-verb | 0.533 | 0.593 | +11% |
| two-clause | 0.365 | 0.398 | +9% |
| complex | 0.340 | 0.370 | +9% |
| nominalization | 0.474 | 0.442 | −7% |
Iteration arc
Each dataset revision targeted a specific failure class; each delivered:
| Version | What was added | Errors / 150 | COMET_c |
|---|---|---|---|
| v1 | single-clause structures + OOV subs | 6 | 0.494 |
| v2 | + multi-clause records (fixed two-clause errs) | 5 | 0.495 |
| v3 | + proper-noun coreference pairs | 0 | 0.492 |
Caveats & honesty
- The fine-tune runs through an HF bf16 pipeline; the base Qwen2.5:3b baseline was measured through Ollama Q4_K_M. Same underlying model, different quantisation. An apples-to-apples re-run is on the list.
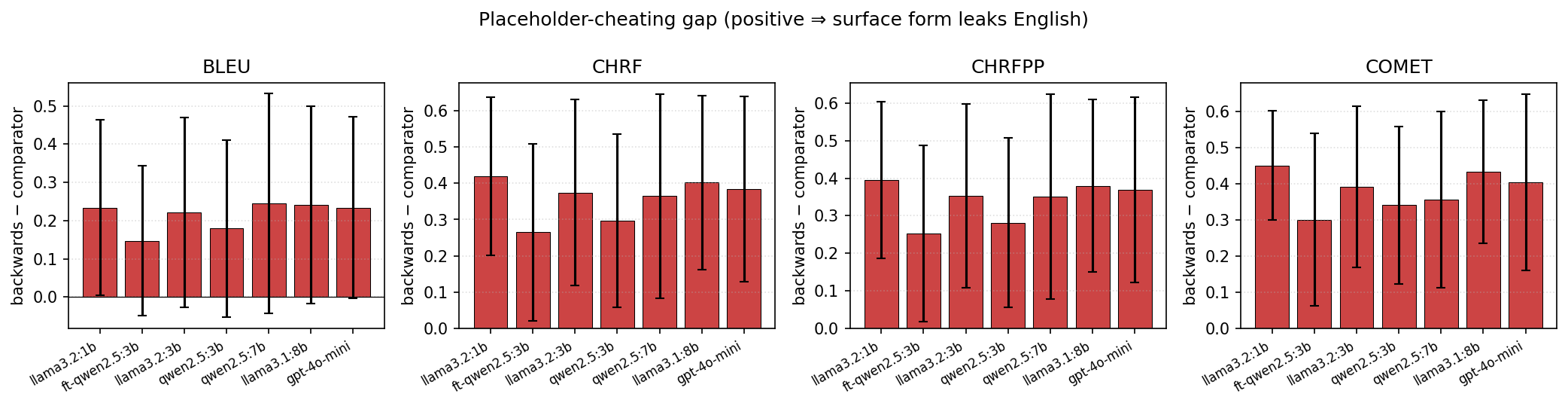
- Absolute COMET_c of 0.492 sits about 0.06 above the unrelated-pair noise floor (˜0.43). The grammar schema caps how much semantic meaning can survive the structural bottleneck; we're nowhere near the ceiling, but the ceiling itself is bounded by the schema.
- Training loss converges to ˜0.02 in ~100 steps — narrow-schema convergence rather than broad generalization. Generalization probe on an unrelated Pydantic schema hasn't been run yet.
- The comparison beats gpt-4o-mini on the cheat-proof metric, but gpt-4o-mini still leads on backwards (0.865 vs 0.792). The fine-tune deliberately produces fewer English-lemma passthroughs (a feature, not a bug — but it's a trade-off).
Next steps
- Scale up — full N=2000 structures + 3 epochs (CLAUDE.md's original recipe); estimated $1.20 data + ~2 h training. Likely closes the nominalization gap.
- Bigger base — same pipeline on Qwen2.5-7B-Instruct or Llama-3.1-8B to quantify how much the gains scale with parameters.
- Apples-to-apples baseline — put base Qwen2.5-3B-Instruct through the same HF pipeline so the fine-tune's isolated effect is cleanly measured.
- Ollama export — merge LoRA → GGUF →
ollama create, then rerun through the existing sweep. Confirms the result holds through the deployed inference stack. - Generalization probe — measure the fine-tune on an
unrelated Pydantic schema (e.g.
Person(name, age, occupation)) vs. the base model. Tells us whether the adapter locked in OVP-specific priors or learned a general schema-adherence skill. - Backward adapter — train a separate LoRA for the structured → English direction so the pipeline runs end-to-end without a proprietary decoder.
Reproduce
cd yaduha-ovp
# 1. Generate the training dataset (~$0.40 at gpt-4o-mini, ~10 min)
N_STRUCTURES=750 bash experiments/run_datagen.sh
# 2. Train the LoRA adapter (~45-60 min on a single RTX 5000 Ada)
uv run --project yaduha-ovp python experiments/finetune/scripts/train.py \
--direction forward --epochs 1 --max-seq-length 2304
# 3. Evaluate on the 150-sentence held-out set (~8 min)
uv run --project yaduha-ovp python experiments/finetune/scripts/run_finetune_eval.py \
--adapter experiments/finetune/adapters/qwen2.5-3b-instruct-forward \
--tag ft-qwen2.5_3b__gpt-4o-mini
# 4. Score + regenerate plots
uv run --project yaduha-ovp python experiments/run_metrics.py \
--input experiments/results/ft-qwen2.5_3b__gpt-4o-mini.jsonl
uv run --project yaduha-ovp python experiments/analyze.py
References
- kubishi/yaduha — core framework
- kubishi/yaduha-ovp — OVP language package (this work lives on the
feature/weakmodelsbranch) - Coleman et al. 2024, LLM-assisted Rule-Based Machine Translation for Low/No-Resource Languages — AmericasNLP
- Coleman et al. 2026, Five-Translator Comparison for No-Resource Machine Translation — LoResMT